
Капча стала неотъемлемой частью нашей жизни. Если вы с ней не сталкивались, вы либо счастливец, либо вас просто не существует. Мелкие рисунки, на которых нужно отметить машинки, велики, светофоры и так дальше, встречаются постоянно и всюду. В особенности нередко грешит сиим Google. Думаете, они необходимы для того, чтоб осознать не бот ли вы? Частично да, но есть у их и другое потаенное назначение. Надеваем шапочку из фольги и читаем далее.

ИИ скоро будет мыслить за нас. Вот лишь что он выдумает?
Может быть, произнесенное смотрится мало странноватым и выдуманным, но у нас с вами есть определенные факты, которые дают осознать в котором конкретно месте «Компания Добра» нас употребляет и преобразует наше с вами свободное время в свою выгоду. Лично мне это не приятно и я не желал бы, чтоб действия и далее так развивались, но пока все конкретно так, а в скором времени может стать еще ужаснее. Хорошо, давайте обо все по порядку…
Что такое капча
Для большего осознания всего, что будет сказано ниже, разглядим поначалу определение того, что мы привыкли именовать таковым словом, как «капча».
Слово это не российское и в оригинале является сокращением от нескольких британских слов. Пишется оно как CAPTCHA, а расшифровка звучит, как «Completely Automated Public Turing test to tell Computers and Humans Apart» (на сто процентов автоматический общественный тест Тьюринга для различения компов и людей).
ИИ бывает весьма полезен: Таинственные радиосигналы из глубочайшего вселенной поможет расшифровать искусственный ум
Тест Тьюринга — это эмпирический тест, мысль которого была предложена Аланом Тьюрингом в статье «Вычислительные машинки и разум», размещенной в 1950 году в философском журнальчике Mind. Его целью было определение возможности машинки ввести человека в заблуждение, заставив мыслить, что он разговаривает с остальным человеком.

Незначительно компьютерного юмора.
Конкретно этот принцип и лежит в базе метода, который описывает, кто пробует выслать запрос на получение инфы от сервера. Обычно, встречаются три главных типа капчи. Это плохо написанные цифрыЯ либо буковкы, которые не сумеет найти комп, математические деяния, которые комп просто выполнит, но не усвоит, что их нужно делать и определение объектов, так любимое Google.
Как работает капча
Мы остановимся конкретно на 3-ем варианте с картинами. Для того, чтоб получить доступ к инфы, нужно отыскать на картинах определенные объекты. К примеру, велики, светофоры, витрины и так дальше.
Рядовая процедура, скажете вы и частично будете правы. Но вы когда-нибудь думали, почему при отчасти неверном ответе, вас все равно пускают к подходящей инфы? Выходит, никому не принципиально, верно ли мы ответим? Можно разъяснить это тем, что в метод заложена определенная погрешность, которая допустима при прохождении этого теста. Представим, это вправду так, но почему таковым методом нередко защищается обычная выдача поисковика? Что такового ужасного случится, если условный бот выяснит сколько звезд с созвездии Ориона? Защита от DDoS-атак? Может быть, но есть и наиболее обычное разъяснение.

Хорошая визуализации того, как боты работают за нас.
Что такое ИИ
Компания Google, как и остальные гиганты промышленности, трудится над созданием собственной версии искусственного ума, либо, как его на данный момент все почаще именуют, ИИ. Я мало скептически отношусь к этому словосочетанию, но оставим подобные рассуждения для иной статьи.
В современном осознании термина ИИ он представляет из себя возможность компа имитировать деятельность человека, в том числе, за счет машинного обучения обучаться определять предметы.
Обычно, для работы таковых систем их нужно поначалу научить на примерах. Другими словами, человек указывает системе автобус и гласит, что это автобус, позже указывает костер и гласит, что это костер. Так длится некое время, опосля что система сама пробует найти где что, а человек гласит права она либо нет.
Полностью может быть, что система капчи от Google нацелена конкретно на это. Беря во внимание млрд запросов, которые юзеры по всему миру посылают на сервер, обучение (педагогический процесс, в результате которого учащиеся под руководством учителя овладевают знаниями, умениями и навыками) может получиться весьма неплохим и полным. Даже если предложить капчу любому десятому юзеру, все равно будет получено большущее количество данных, которые компания сумеет употреблять для обучения собственных систем. При всем этом, на сто процентов в автоматическом режиме.
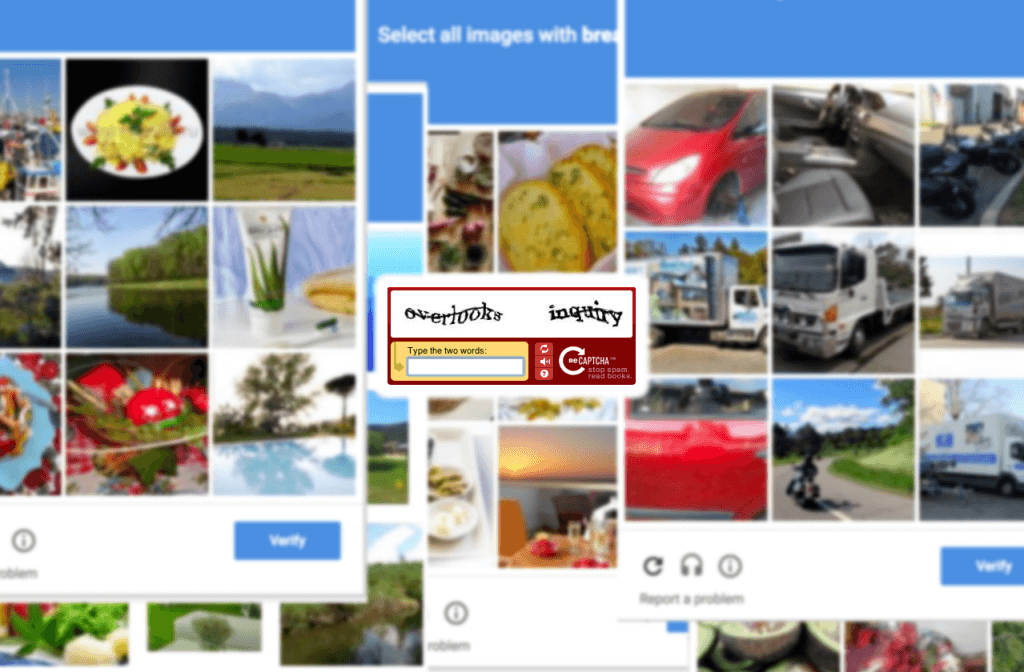
Огромное количество вариантов капчи, с которой мы сталкиваемся любой денек
Как Google пробует нас употреблять
Естественно, официально это не подтверждается, но судя по всем фактам компания конкретно употребляет нас. Доказательством будет то, что капча возникает так нередко и почему-либо время от времени пропускает ошибки.
Если это вправду так, лишь представьте, сколько средств компания сберегает на армии профессионалов, которые должны учить систему, распознающую изображения. Так же произнесенное относится и к тем случаям, когда для вас предлагается прочесть размытый текст на фасадах домов. В данной нам ситуации система может учиться определять номера домов при сканировании улиц для разных картографических сервисов.

Капча с номерами домов
К примеру, на картинке выше приведены несколько примеров капчи с номерами домов. С одной стороны это просто не весьма контрастное изображение, которое быстрее всего не сумеет распознать бот. С иной стороны, почему конкретно номера домов? Номера домов — это истинное золото для карт от Google. Создателям сервиса не нужно будет расставлять дома раздельно. Система сумеет сама осознать где какой номер и нанести его на карту в автоматическом режиме. А мы же позже к тому же проверим приобретенный итог, когда не найдем подходящего дома и отправим правки на рассмотрение, получив в качестве вознаграждения эфимерный статус члена команды Google. Ведь номера домов не нарисованы, а реально сфотографированы и быстрее всего авто Google, которые во всю колесят по дорогам, снимая улицы для «панорам».
В дальнейшем это поможет и работе автономных каров. Для доказательства этого, стоит вспомянуть рисунки капчи со светофорами, пешеходными переходами и перекрестками. Конкретно такие рисунки в не самом наилучшем качестве будут выдавать камеры автопилота и системе нужно будет их распознать. Пока автономных машин в широком осознании нет, но данные для их уже копятся.

Капча с поиском частей дорожной инфраструктуры
Доп свидетельством того, что это конкретно Google пробует накачать свои сервисы информацией являются китайские системы идентификации, которые сводятся к обычный операции, вроде установки галочки в подходящем месте либо свайпа по экрану. У их не работает Google и им не приходится заниматься схожим сбором данных.
Пример китайской капчи
Очередной пример китайской капчи
Не считая картинок, Google дает распознать голосовой текст. Осознаете к чему я? У Google есть собственный помощник, которому для обучения нужно с кем-то разговаривать и не только лишь слушать запросы, да и осознавать на сколько отлично человек осознает то, что ему произнесли. Для этого и употребляется система голосовой капчи.
Выходит, эпидемия капчи блуждает от юзера к юзеру. На мой взор это излишний раз подтверждает теорию, приведенную выше.
Как думаете, может такое быть по сути? Напишите в комментах и поучаствуйте в опросе, размещенном ниже.









